On string lengths
This story dates back from when I worked at Strava.
The Strava app has a feature where users can mention each other in comment boxes: when you start typing someone’s name, it triggers an autocomplete box to let you pick a friend’s name, and then bolds and links the text to the profile of the user being mentioned. At the time the mentioning feature was launched, the app didn’t support the full range of Unicode codepoints (practically speaking: emojis were excluded from Strava).
A short while after adding support for emojis, we observed an issue when users would use both mentions and emojis in the same comment:
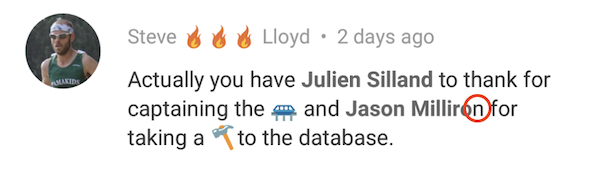
The bolding was off - and the faulty offset was apparently related to the number of emojis preceding the mention:

Digging Deep
The issue occurred on both our official Android and iOS clients, which hinted at a server-side issue. Hours were spent digging into the mentions logic on the server but no obvious flaws were found. And at the API level, the response returned by the server looked legit:
{
"text": "👏👏👏👏👏 Jason Milliron Julien Silland",
"mentions_metadata": [{
"uri": "strava://athletes/6527",
"start": 6,
"end": 19
}, {
"uri": "strava://athletes/136697",
"start": 21,
"end": 34
}]
}For backwards compatibility, mentions were added to the comment object as a mentions_metadata field, an array of objects that contain the start and end index of a single mention, and the target of the link to go to when the link is clicked. The indices in that response are correct: the first mention begins at character 6 and ends at character 19, the second one starts at character 21 and ends at 34:
| Sections | 👏👏👏👏👏 | Jason Milliron | Julien Silland |
||
| Indices | 0 – 4 | 5 | 6 – 19 | 20 | 21 – 34 |
On the wire, this string was encoded in UTF-8 – for future reference, here’s the hex version of the raw UTF-8 bytes:
| 0xF0 | 0x9F | 0x91 | 0x8F | 0xF0 | 0x9F | 0x91 | 0x8F |
| 0xF0 | 0x9F | 0x91 | 0x8F | 0xF0 | 0x9F | 0x91 | 0x8F |
| 0xF0 | 0x9F | 0x91 | 0x8F | 0x20 | 0x4A | 0x61 | 0x73 |
| 0x6F | 0x6E | 0x20 | 0x4D | 0x69 | 0x6C | 0x6C | 0x69 |
| 0x72 | 0x6F | 0x6E | 0x20 | 0x4A | 0x75 | 0x6C | 0x69 |
| 0x65 | 0x6E | 0x20 | 0x53 | 0x69 | 0x6C | 0x6C | 0x61 |
| 0x6E | 0x64 |
On the client side, the bytes were decoded into the native string type and decorated using the routines proper to their platform, in Java on Android:
String comment = new String(bytes, StandardCharsets.UTF_8);
SpannableString stylable = new SpannableString(comment);
stylable.setSpan(new StyleSpan(Typeface.BOLD), mention.start, mention.end, …);And in Objective-C on iOS:
NSString *comment = [[NSString alloc] initWithData:bytes
encoding:NSUTF8StringEncoding];
stylable = [[NSMutableAttributedString alloc] initWithString:comment];
[stylable addAttribute:(NSString *)kCTFontAttributeName
value:(__bridge id)font
range:mention.range];The code on both platforms is legible and straightforward, and doesn’t look to be flawed with an off-by-x index issue. It’s a wild guess but since the API response looks correct, and the client code looks correct, we should look at a deeper level to understand the discrepancy.
As it turns out, Java and Objective-C have striking similarities in how they represent strings. Both have good Unicode support but both are also relatively ancient: Java’s JDK 1.0 was released in 1995 and Cocoa’s Foundation Kit (which contains NSString) was developed for NeXTSTEP 3.0, which shipped in 1992. Unicode 1.0 was published in 1992 and played a role in how the standard libraries of each language would encode strings.
With fewer than 65K codepoints defined at the time, it made sense to encode strings using UCS-2, a precursor to UTF-16: strings would be backed by an array of fixed 16-bit chunks. This was both forward-looking and practical: although there would be a memory penalty when representing ASCII-compatible text (which would generally fit on 8-bit chunks), opting for 16-bit chunks opened up compatibility with most of the world’s scripts and made character iteration fast and easy.
However, this direct equivalence between characters and items in the backing array breaks for emojis and other characters that take more than a single chunk to represent.
Different Strokes
When a human thinks about string length and indices, they generally reason about characters they can see on-screen. A programming language will generally reasons in the length of the underlying structure that stores the string. What is supposed to be an implementation detail becomes a leaky abstraction. As it turns out, most languages are leaky by default and few of them do the intuitive thing when computing the length of a string.
The following table lists the result of computing the length of the string “👏👏👏👏👏 Jason Milliron Julien Silland” across a few popular languages:
| Language | Result | Method |
|---|---|---|
| Java | 40 | String.length() |
| Ruby | 35 | String.length |
| Go | 50 | len(…) |
| Obective-C | 40 | NSString length |
| Rust | 50 | std::string::String.len() |
| JavaScript | 40 | String length |
| Swift 3 | 35 | This was using the now deprecated .characters view |
| Swift 4+ | 35 | String.count |
| Python 2 | 40 | len(…) |
| Python 3 | 35 | len(…) |
- Java, Objective-C and JavaScript all use UCS-2 for their strings: the first 5 ‘👏’ each occupy 2 elements in the array, and the remaining 30 codepoints each occupy one: (5 × 2) + 30 = 40
- Ruby and Swift operate at the grapheme cluster level and each return 35
- Go and Rust represent strings as an array of UTF-8 bytes: the first 5 ‘👏’ occupy 4 elements each, and the remaining 30 codepoints each occupy 1: (5 × 4) + 30 = 50
- Strings in Python 3 are strongly typed as such, but they were raw byte arrays in Python 2 and lower
| 👏👏👏👏👏 | Jason Milliron | Julien Silland | ||||
| UCS-2 | 5 × 2 | 1 | 14 | 1 | 14 | 40 |
| UTF-8 | 5 × 4 | 1 | 14 | 1 | 14 | 50 |
| Human | 5 | 1 | 14 | 1 | 14 | 35 |
The root cause of the rendering issue is that the indices returned from API operate in terms of human characters whereas both clients use them to index an array of 16-bit chunks. When a character such as 👏 takes 32 bits to represent, the indices are off. It’s clear from this example that you should be skeptical of the commonly available methods to obtain the length of a string. There are only a handful of situations where it can be relied on:
- You are positively certain that it measures what you are seeking to measure
- You will never need to assert the equivalence of the same string across multiple programming languages
- You strongly guard against the presence of any character that would throw the calculation off
A more realist stance is that if your code operates on strings (measuring length, indexing, trimming, splitting), it should be ready to handle the complexity that comes with it - this is espcially important for content that is user-submitted.
Digging Deeper
The solution here is to break down what is really a string of bytes into chunks that make sense for humans – these are called “grapheme clusters” in the Unicode specification. However, doing so isn’t a simple matter of accounting for characters that take twice or four times the length of characters in the ASCII range. Unicode defines modifiers and zero width joiners which are used to modify and link the semantics of another codepoint.
For instance, the single emoji 👨🏿🦲is actually a combination of three different codepoints and one “joiner” character that serves as an hint to implementors that the codepoints on either side of it participate to the same cluster:
| Character | 👨🏿🦲 | |||
| Codepoints | Man | Dark Skin Tone | Zero Width Joiner | Bald |
| Values | U+1F468 | U+1F3FF | U+200D | U+1F9B2 |
| UTF-8 hex | F0 9F 91 A8 | F0 9F 8F BF | E2 80 8D | F0 9F A6 B2 |
In a language such as Go, this single character would be reported as having a length of 15!
Unicode defines grapheme clusters as part of the standard: these are rules for segmenting strings into chunks that map well to what a human would consider to be characters in a string. Most high-level languages such as Java, Objective-C and Swift expose this higher-level abstraction:
- Java’s documentation on character representations, and especially
String.codepointAt(index),Character.isHighSurrogate,isLowSurrogate,isSupplementaryCodePoint - Objective-C’s NSString and especially
rangeOfComposedCharacterSequenceAtIndex - Swift’s documentation on strings and characters documentation
- Go documentation on strings and normalization