The Unicode Character Set
This article is the first in a series intended to demystify the Unicode standard and explore in some depth the aspects that programmers have issues with. It is recommended that you follow the articles in sequence, as the concepts in later articles build upon the ones explained in earlier ones.
- I � Unicode
- The Character Set (this article)
- The Encodings
- The Algorithms
To understand Unicode’s contributions to the space of character sets, it’s worth taking a look at what the landscape looked like before it came around:
- character sets were numerous: over the decades that saw the explosion of enterprise and personal computing, dozens if not hundreds of character sets were defined. Some were defined as pure standards (ASCII, EBCDIC), while others were tied to platforms (Windows 125x, Mac OS Roman)
- character sets were limited: they generally targeted regions (“ISO 8859-1 Western Europe”) or scripts (“Windows 1254” for Turkish) but none would really be able to capture the full breadth of the world’s languages by itself. At best, they defined a few thousand characters
Space
Unicode set out to solve those issues by primarily giving itself space: rather than collecting the characters and putting them in a set, Unicode first defined the structure in which the characters would exist: in its first version, the space of all characters was specified as an array of 65,536 elements (216).
As the standard progressed in its task to inventory the world’s characters, it became clear that the initial space was going to run out. To that effect, the second major version of Unicode allocated 16 more planes, each having 65,536 elements of their own. The total number of possible characters is 1,114,112 (17 × 65,536)
There are way fewer known characters in all of the world’s scripts and languages. From that point on, Unicode had plenty of room to grow.
The very first of the 17 planes is called the Basic Multilingual Plane (BMP) and contains characters that cover most of the written languages on Earth:
Addresses and names
Second, Unicode defined an addressing scheme. In previous character sets, there was an immediate equivalence between the character and the bytes you used for representing that character. In contrast to that approach, the Unicode character set only concerns itself with giving each character an address in the array (its U+ number) and a name.
The number and the name define what is called a code point. All code points are created equal — some have semantics but from an addressing standpoint, there is no fundamental difference between characters such as U+006B LATIN SMALL LETTER K (k), symbols such as U+27A4 BLACK RIGHTWARDS ARROWHEAD (➤) and emojis such as U+1F63B smiling cat face with heart-shaped eyes (😻).
It’s in the Unicode mission statement:
Unicode provides a unique number for every character
Code points bonanza
Unicode defines over a hundred thousand code points that cover over a hundred scripts (a script is a writing system such as Arabic, Cyrillic, ancient Greek, Hebrew, Latin, etc…). Because there is so much room to grow, Unicode also defines characters that are used in music or in mathematics.
Because there is so much space available, Unicode can afford to define code points that resemble one another but that have different semantics. U+03A3 GREEK CAPITAL LETTER SIGMA (Σ) and U+1D6BA MATHEMATICAL BOLD CAPITAL SIGMA (𝚺) are different code points even though the latter stems from the former.
Look-alike characters also get distinct code points: U+0430 CYRILLIC SMALL LETTER A (а) is a different character than U+0061 LATIN SMALL LETTER A (a). Same goes for U+03B2 GREEK SMALL LETTER BETA (β) and U+00DF LATIN SMALL LETTER SHARP S (ß). In other words, Unicode doesn’t concern itself with the shape of a character, it concerns itself with its formal definition and its function. And since there’s plenty of room, Unicode can be extremely specific to define all the variations of what might otherwise pass for the same character.
The minutiae can go quite far. An interesting example is that the Western latin script and its numbering system is fairly prevalent in the world, and it is common that other scripts (Arabic, Cyrillic, Hebrew, etc…) need to use latin characters in contexts where it mixed with local ones.
For mostly aesthetic reasons, the Japanese and Chinese languages have defined a different mode for writing those, where, in order to match the natural width of ideographs, the physical width of the glyph (the space taken by the character on the screen) is bigger than it normally would be.
Unicode defines those as separate code points from the original one they are based on. For instance, U+FF43 FULLWIDTH LATIN SMALL LETTER C (c) is intrinsically the same as U+0063 LATIN SMALL LETTER C (c) but it is defined separately from the standpoint of Unicode.
Conversely, there is a also a set of Katakana characters that are defined as “half-width” (e.g. U+FF76 HALFWIDTH KATAKANA LETTER KA カ) compared to their natural full-width base (U+30AB KATAKANA LETTER KA カ).
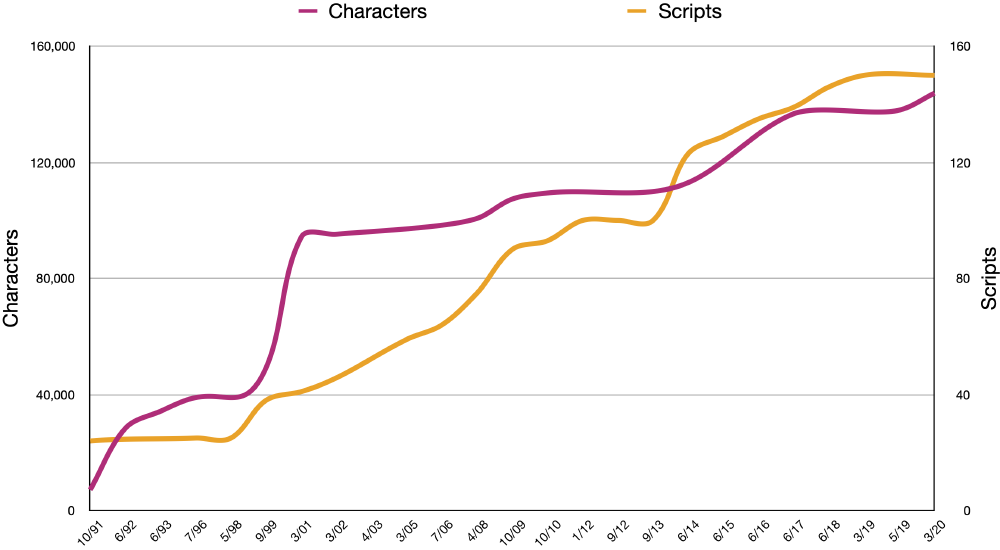
Versions
Lastly, Unicode took care of defining versions of its character set. As of this writing, the most recent version of Unicode is 13, and it defines 143,859 code points. Unlike other character sets, Unicode planned ahead to allow for the character set to grow and for these changes to roll-out in a way that is backwards-compatible.
When new characters such as emojis came around, all that needed to happen is to assign each of them a U+ number and a name, and that was that.
Fonts and rendering
After new code points are defined in a Unicode release, two more steps need to be taken for the end user to actually be able to benefit from it:
- OS vendors (Apple for macOS, Google for Android, etc…) need to bump up their Unicode version to include support for those characters
- Font vendors (e.g. Twitter, Microsoft, Apple, Google) need to add glyphs (graphical symbols) to represent those characters.
As mentioned before, Unicode doesn’t focus on character shapes but end users need that! Fonts embed the data for converting Unicode code points into glyphs, which are what you see on your screen. They are orthogonal to the Unicode standard but they are critical to the user experience of the Unicode character set.
A “missing character” in a string you see on screen might be because the operating system doesn’t recognize it, or because there’s no available font that knows what to make of that code point (or sequence of code points). No single font can represent all Unicode code points because of size limits with popular font file formats. As a result, vendors segment their font files by script or sometimes regions.
If you were to use an old version of, e.g. Android, newer emojis would not render correctly but would also not crash your system: the Unicode implementation would just see a code point it doesn’t know about and handles it
- If this is an issue with the underlying encoding, the character should be replaced U+FFFD
REPLACEMENT CHARACTER(�) - If there is no available font to render the code point, the system should use a generic replacement glyph, e.g. “”